
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 서버
- FastAPI
- mnist
- Google Speech To Text
- ajax
- 스파르타코딩클럽
- KoBART
- html
- jquery
- Linux
- Django
- Transfer_Learning
- 우분투2004
- ubuntu
- UbuntuServer
- Kaggle
- Custom Classes
- keras
- model
- Model Adaptations
- 모델적응
- KoBERT
- Phrase Sets
- Flask
- 4주차
- AWS
- EC2
- Ubuntu2004
- 과일종류예측
- 가장쉽게배우는머신러닝
- Today
- Total
영웅은 죽지 않는다
[NLP] KoBART Chit-Chat bot(챗봇) 모델링 및 학습 과정 본문
[단독] SK텔레콤, 요약 잘하는 AI모델 공개…'자연어이해' 기술 강화 | 아주경제
[사진=게티이미지뱅크]SK텔레콤 연구진들이 한국어 뉴스나 문서를 읽고 고품질 요약문을 만들어내는 능력이 뛰어난 인공지능(AI) 언어처리 모델을 조용히 공개했다. 이로써 SK텔레콤은...
www.ajunews.com
GitHub - SKT-AI/KoBART: Korean BART
Korean BART. Contribute to SKT-AI/KoBART development by creating an account on GitHub.
github.com
2020년도에 SKT에서 한국어 AI 자연어처리 모델인 KoBART를 만들었죠.
KoGPT-2에 이은 SKT의 세번째 한국어 자연어처리 모델이랍니다.
SKT 공식 github에 간략한 레퍼런스가 여럿 있는데,

나는 이 중 챗봇을 구현하고 싶어 KoBART ChitChatBot 레퍼런스 예시로
직접 구한 데이터를 바탕으로 학습시켜보았습니다
GitHub - haven-jeon/KoBART-chatbot: KoBART chatbot
KoBART chatbot. Contribute to haven-jeon/KoBART-chatbot development by creating an account on GitHub.
github.com
참고로 여러 기사들을 본 결과 KoBART는 문서 요약에 특히 강한 것 같네요
1. 기본 전처리
데이터는 질문(Q), 대답(A), 해당 질의응답에 대한 라벨(label) 이렇게 총 3개의 columns로 구성되어 있으면 됩니다.

보안상 데이터는 가렸지만, 대략 파악은 될겁니다
위 KoBART의 Chit-Chat 페이지에 가보면 예시 데이터도 있습니다.
그냥 테스트만 해보고 싶다면 그걸 이용해도 무방합니다.
위와 같은 데이터셋을 만들기 위해 아래와 같이 전처리 코드를 만들었습니다.
import numpy as np
import pandas as pd
filename = 'data.xlsx'
data = pd.read_excel(f'{filename}')
datadf = data[data['QUE'].notnull()] # 데이터 null값 제거
intent_train = []
question_train = []
answer_train = []
intent_val = []
question_val = []
answer_val = []
intent_test = []
question_test = []
answer_test = []
# intent 하나당 question이 10개 단위로 묶여있음 (본인 데이터별로 임의 조정 필요)
for i in range(0,len(df),10):
for j in range(10):
if j < 7:
# train set (70%)
que = df['QUE'].iloc[i+j].replace('\n','')
ans = df['ANS'].iloc[i].replace('\n','')
intent = df['인텐트명'].iloc[i]
print('train data: ', que, ans)
question_train.append(que)
answer_train.append(ans)
intent_train.append(intent)
elif j >= 7 and j < 9:
# validation set (20%)
que = df['QUE'].iloc[i+j].replace('\n','')
ans = df['ANS'].iloc[i].replace('\n','')
intent = df['인텐트명'].iloc[i]
print('validation data: ', que, ans)
question_val.append(que)
answer_val.append(ans)
intent_val.append(intent)
else:
# test set (10%)
que = df['QUE'].iloc[i+j].replace('\n','')
ans = df['ANS'].iloc[i].replace('\n','')
intent = df['인텐트명'].iloc[i]
print('test data: ', que, ans)
question_test.append(que)
answer_test.append(ans)
intent_test.append(intent)
print('*'*100)
print()
학습, 검증, 테스트의 과정을 거치기 위해 7:2:1의 비율로 데이터를 나누었으며
df_train = pd.DataFrame(zip(question_train, answer_train, intent_train), columns=['Q','A','label'])
df_val = pd.DataFrame(zip(question_val, answer_val, intent_val), columns=['Q','A','label'])
df_test = pd.DataFrame(zip(question_test, answer_test, intent_test), columns=['Q','A','label'])
df_train.to_csv('train.csv', index=False, encoding='utf-8-sig')
df_val.to_csv('validation.csv', index=False, encoding='utf-8-sig')
df_test.to_csv('test.csv', index=False, encoding='utf-8-sig')
print(len(df_train), len(df_val), len(df_test))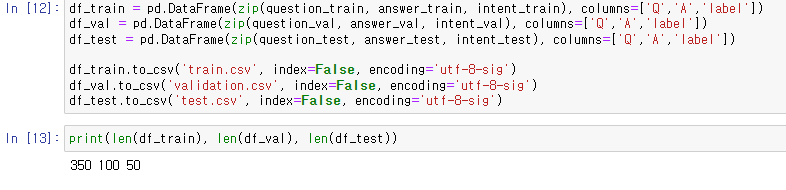
저같은 경우 총 500개의 데이터를 350, 100, 50개로 나누어지게끔 했습니다.
2. 라이브러리 설치 및 학습 준비
위 깃허브 레퍼런스에 나와있듯이 일단 KoBART 모델을 다운로드 한 후
레포지토리에 올라와있는 것을 clone 받습니다.
이 과정을 무시하고 진행하면
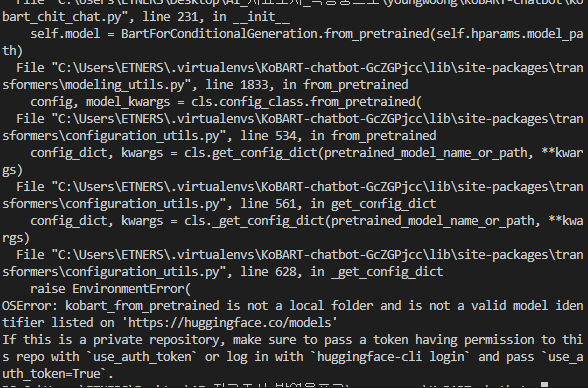
위와 같은 에러가 나게 됩니다.
깃허브 리드미에서 보여주듯 레퍼런스에 라이브러리 설치 후 pretrain된 모델을 가져오는 것이
아래 코드들을 입력해야 가능한 것이었습니다
아마 토큰,, 관련 설정을 하는 작업을 하는 것 같네요. 자세한 의미는 모르겠습니다ㅠ
무튼 저는 가상환경을 생성하였고 bash 창에서 해당 경로로 클론받은 후 터미널 창에서 설치를 진행했습니다
# KoBART 설치
pip install git+https://github.com/SKT-AI/KoBART#egg=kobart
pip install pandas
pip install pytorch_lightning==1.2.1
git clone --recurse-submodules https://github.com/haven-jeon/KoBART-chatbot.gitpython
>>> from kobart import get_pytorch_kobart_model, get_kobart_tokenizer
>>> get_kobart_tokenizer(".")
>>> get_pytorch_kobart_model(cachedir=".")
문제가 없다면 커맨드에 위 명령어를 입력
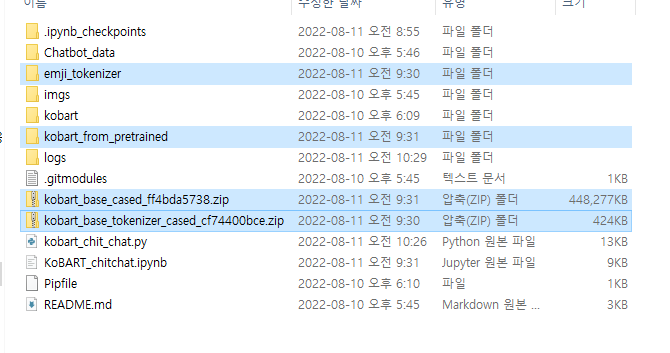
클론받아와진 폴더에 아래 네 개의 폴더와 압축폴더가 생겼을겁니다.
압축폴더를 굳이 안풀어도 됩니다. (기본 폴더들이 나옵니다)
클론 & 라이브러리 설치 및 모델 다운로드를 하고 난 뒤에는
클론받은 폴더 안에서 ~/KoBART-chatbot/Chatbot_data 하위에
train.csv, validation.csv, test.csv 를 순차적으로 집어넣습니다.
기존에 있는 train.csv와 test.csv는 삭제했습니다.
3. 에러 해결
1) gpu 사용 문제
위 과정을 거친 후 레퍼런스대로 학습을 시켰더니
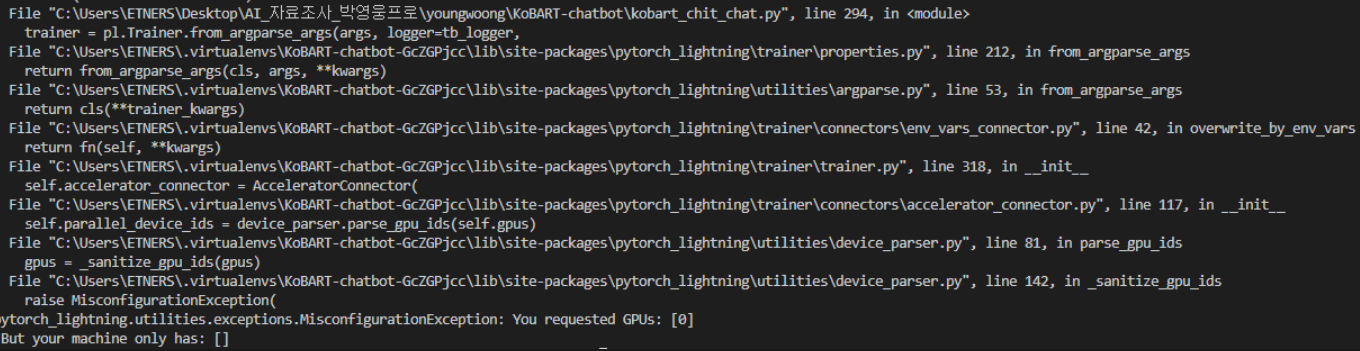
pytorch_lightning.utilities.debugging.MisconfigurationException: You requested GPUs: [0] But your machine only has: []
위 에러를 맞이했습니다. 가상환경에 GPU 세팅을 했다고 생각했는데 잘 되지 않았던 모양입니다.
NVIDIA와 CUDA를 설치한 기억이 있는데, 자세히 알아보니 cuDNN이 없어서 났던 에러였습니다.
https://github.com/Lightning-AI/lightning/issues/1314
https://mopipe.tistory.com/159
위 글들을 참고하여 해결했고, 저는 아래 코드를 추가로 입력하여 해결했습니다
python
>> import torch
>> print(torch.cuda.is_available()) # False가 난 것으로 보아 gpu 작동이 되지 않음을 확인pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
2) Cross Entropy 에러
그 다음에는
RuntimeError: "nll_loss_forward_reduce_cuda_kernel_2d_index" not implemented for 'Int’
위 에러를 맞이했고, 구글링해보니
labels의 dtype을 수정해야 한다는 것을 보았습니다. (https://github.com/dnn-security/Watermark-Robustness-Toolbox/issues/2)
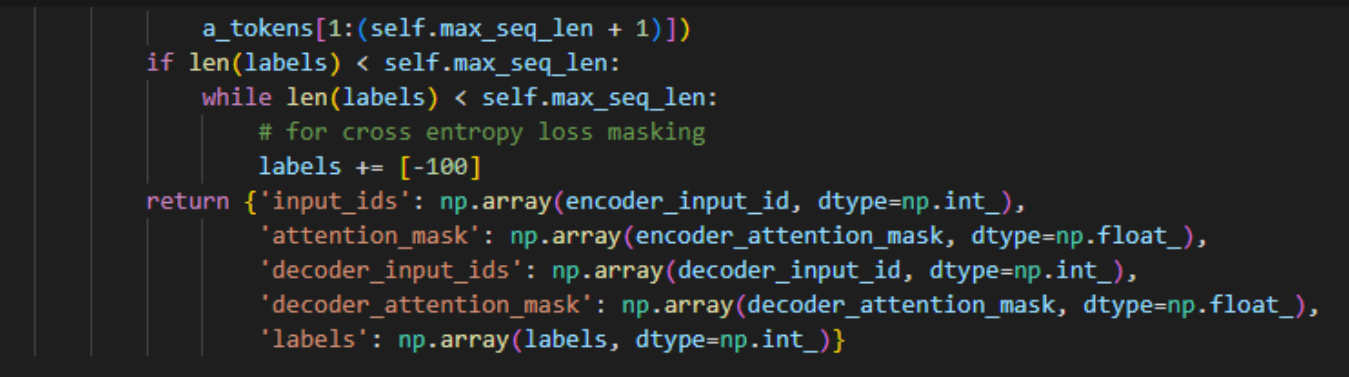
기존 train.py를 보면 ChatDataset 클래스 내부에 __getitem__ 함수 내부에
위와 같이 나와있는 부분이 있는데, 이 곳이 문제였습니다.
왜 문제인지는 잘 모르겠지만,, 아무튼 그렇답니다
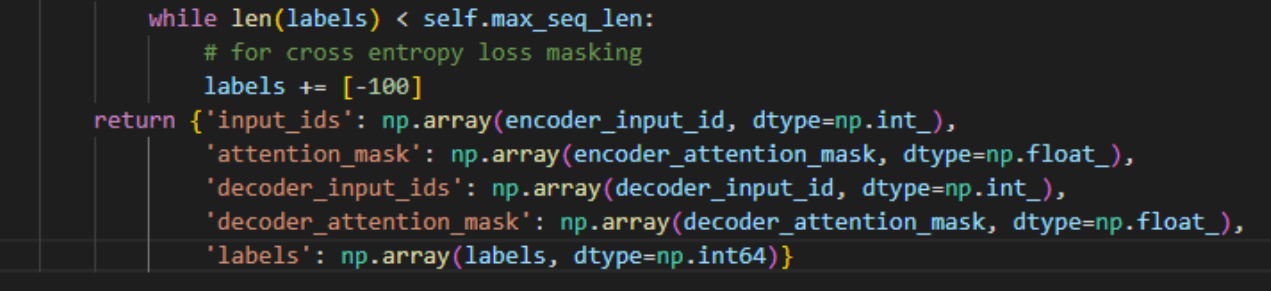
위처럼 labels의 dtype을 np.int_에서 np.int64로 바꾸었더니 고쳐졌습니다.
아마 제 데이터 기준으론 표현 가능한 값을 64비트까지 늘려주어야 했던 것 같습니다.
4. 학습 실행
python kobart_chit_chat.py --gradient_clip_val 1.0 --max_epochs 3 --default_root_dir logs --model_path kobart_from_pretrained --tokenizer_path emji_tokenizer --chat --gpus 1
모든것이 문제가 없다면 아마 학습 epoch가 돌기 시작할겁니다.
기본 epoch는 3인데, 제 gpu와 컴퓨터 환경 기준 한 epoch에 3분정도 돌았던 거 같습니다
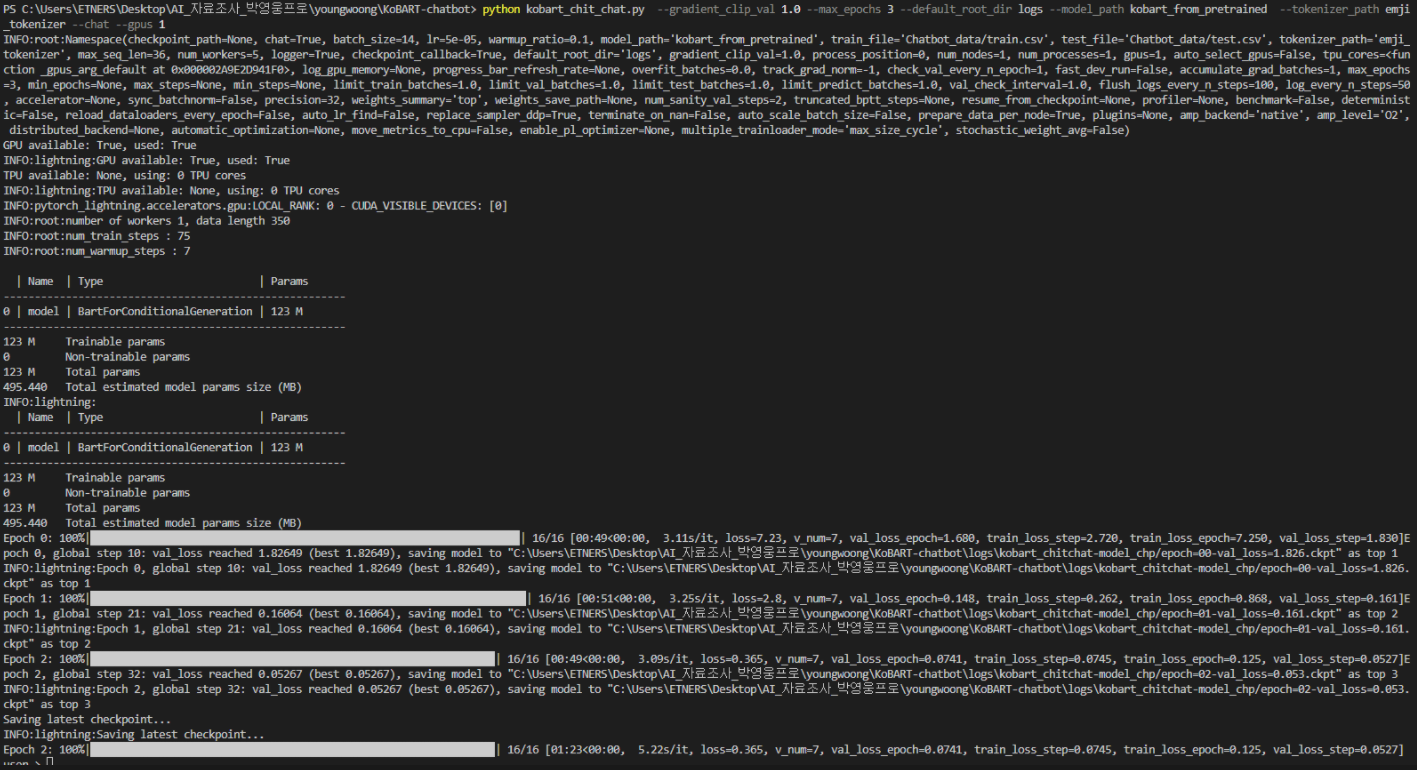
한 epoch가 돌때마다, checkpoint 형식의 로그가 KoBART-chatbot / logs 폴더 하위에 남게 됩니다.
저는 첫 결과를 보고, val_loss값이 낮기는 하지만 정확도를 더 높이고 싶어서 epoch 수를 3에서 20으로 늘립니다.
python kobart_chit_chat.py --gradient_clip_val 1.0 --max_epochs 20 --default_root_dir logs --model_path kobart_from_pretrained --tokenizer_path emji_tokenizer --chat --gpus 1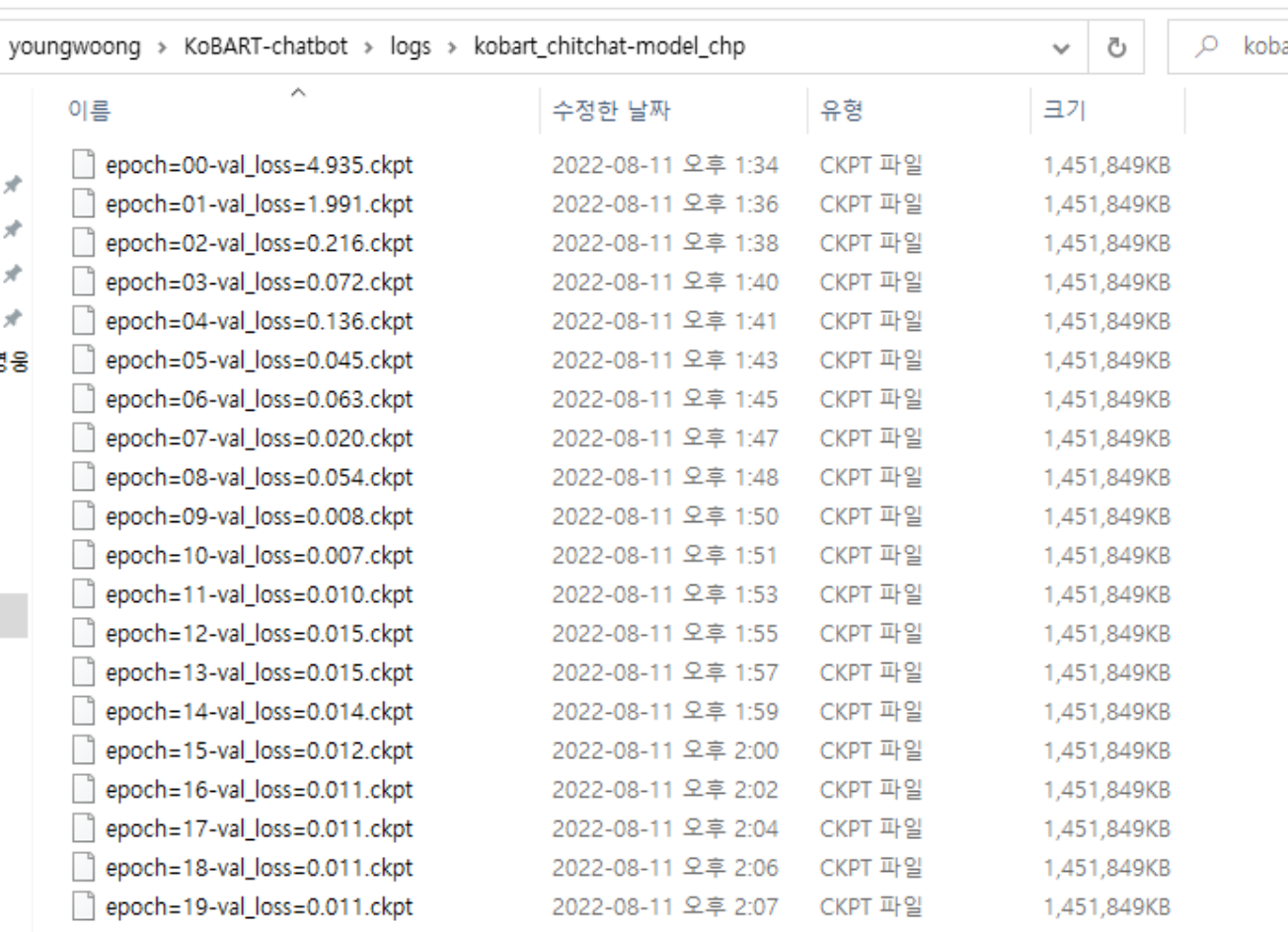
많이 좋아진 것 같죠?
위 checkpoint 파일 이름에 validation loss값을 각 epoch별로 넣었는데,
epoch가 한 10번에서 15번정도가 되면 0에 매우 가깝게 수렴이 되는 것을 확인할 수 있네요
그래서 저는 이후에는 epoch를 15번으로 낮추었습니다.
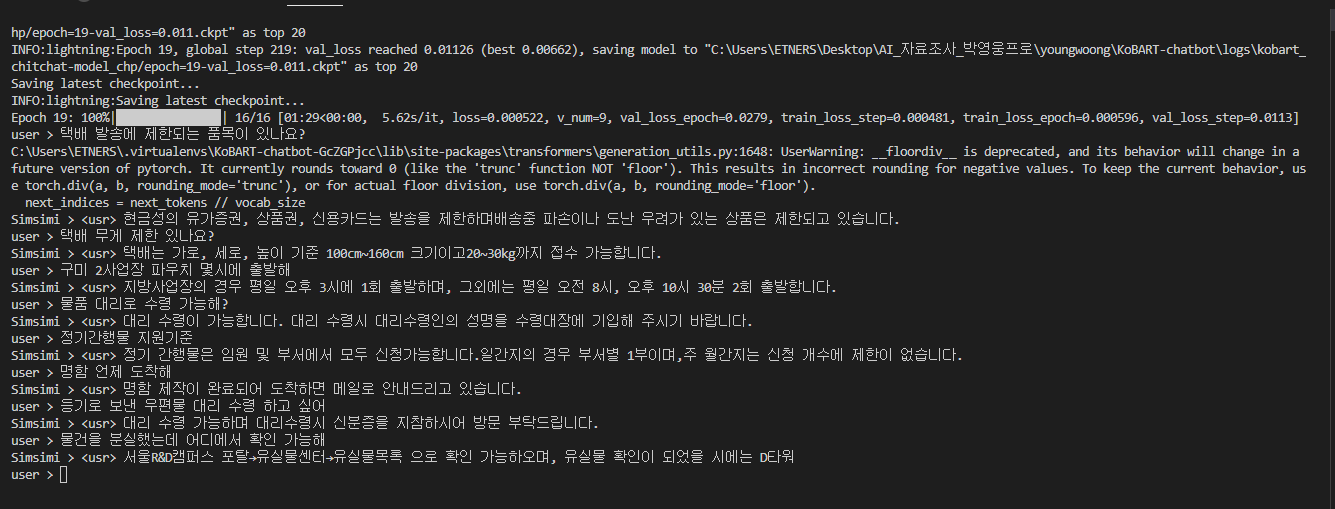
모든 학습이 끝나면 코드 가장 하단에 while문으로 들어갑니다
model을 직접 테스트해볼 수 있는 부분인데, 여기서 임의로 input값을 넣어보며 테스트할 수 있습니다
조금 테스트 해본 결과 제 데이터 기준 성능이 좋았습니다.
여기까지는 문제 없이 이루어졌습니다.
그러나 제가 이 이후에 원했던 것은 성능 측정이었는데,
KoBERT와 KoBART 중 AI 질의응답 서비스에 있어서
같은 데이터셋에 대해 어느 모델이 더 성능이 좋은지 분석해보기 위해서 였습니다.
그러기 위해서는 완성된 모델을 다른 py파일에서 불러온 후 test.csv로 질문을 모델에 넣었을 때의 결과와, 해당 index에 있는 답변을 비교하며 정확도를 측정하고자 했습니다.
그런데 체크포인트 형식인 .ckpt가 어떻게 저장이 되고 어떻게 불러와서
어떤 방식으로 사용할 수 있는지 감이 잘 잡히지 않네요
이 부분은 추가적으로 알아본 후 다시 정리해볼 예정 ~
'Programming > NLP' 카테고리의 다른 글
| [NLP] Pytorch Lightning 기반 KoBART 학습, checkpoint(ckpt) 불러오기 및 테스트, 성능 측정 (0) | 2022.08.16 |
|---|
