
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Custom Classes
- KoBART
- Flask
- 서버
- 과일종류예측
- Django
- Transfer_Learning
- Kaggle
- KoBERT
- Model Adaptations
- EC2
- Linux
- Phrase Sets
- html
- 모델적응
- Google Speech To Text
- 4주차
- 스파르타코딩클럽
- jquery
- UbuntuServer
- 우분투2004
- keras
- ajax
- Ubuntu2004
- FastAPI
- ubuntu
- 가장쉽게배우는머신러닝
- model
- AWS
- mnist
- Today
- Total
영웅은 죽지 않는다
[NLP] Pytorch Lightning 기반 KoBART 학습, checkpoint(ckpt) 불러오기 및 테스트, 성능 측정 본문
[NLP] Pytorch Lightning 기반 KoBART 학습, checkpoint(ckpt) 불러오기 및 테스트, 성능 측정
YoungWoong Park 2022. 8. 16. 16:18
[NLP] KoBART Chit-Chat bot(챗봇) 모델링 및 학습 과정
[단독] SK텔레콤, 요약 잘하는 AI모델 공개…'자연어이해' 기술 강화 | 아주경제 [사진=게티이미지뱅크]SK텔레콤 연구진들이 한국어 뉴스나 문서를 읽고 고품질 요약문을 만들어내는 능력이 뛰어
heroeswillnotdie.tistory.com
이전 글에 이어서 포스팅합니다.
1. 기존 학습코드 분석
KoBART github에서 제공하는 레퍼런스대로 학습을 마치고 나면,
클론받은 폴더 하위의 logs / kobart_chitchat-model_chp에 체크포인트 형식의 학습 로그가 아래처럼 저장될 것입니다.

딥알못인 저는, 일반적으로 생각했을 때
체크포인트는 말 그대로 학습 로그로서, 학습이 비정상적으로 종료되거나 중지했을 때
이후에 이어서 학습할 수 있는 환경을 만들어주는 것이라고 생각했습니다
사실 맞는 말이긴 합니다.
PyTorch에서 일반적인 체크포인트(checkpoint) 저장하기 & 불러오기
추론(inference) 또는 학습(training)의 재개를 위해 체크포인트(checkpoint) 모델을 저장하고 불러오는 것은 마지막으로 중단했던 부분을 선택하는데 도움을 줄 수 있습니다. 체크포인트를 저장할 때는
tutorials.pytorch.kr
위 파이토치에서 제공하는 튜토리얼에 따르면,
일반적으로 체크포인트를 저장하고 로드하는 방법을 잘 설명해주는데
추론(inference) 또는 학습(training)의 재개를 위해 체크포인트(checkpoint) 모델을 저장하고 불러오는 것은 마지막으로 중단했던 부분을 선택하는데 도움을 줄 수 있습니다.
라고 합니다.
하지만 kobart_chit_chat.py에서 작성된 코드와는 차이가 있죠
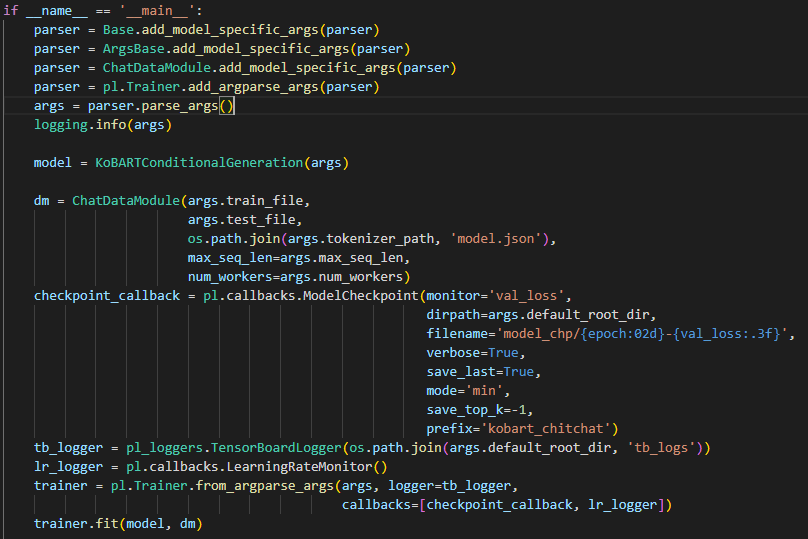
여기서는 파이토치 라이트닝을 기반으로 Model이 train되는 동안 checkpoint를 callback(저장)하는 함수를 실행시켰습니다.
파이토치 라이트닝은 PyTorch에 대한 High-level 인터페이스를 제공하는 오픈소스 Python 라이브러리 라고 합니다.
Pytorch Lightning 공식 레퍼런스와 구글링을 통해 다양한 시도를 해보았는데,,
일단 KoBART 모델을 파악하는게 우선시되어야 했습니다ㅠ
우리가 PyTorch Lightning을 써야 하는 이유
다음 글은 PyTorch Lightning 라이브러리에 있는 여러 내용들을 참고하여 작성했습니다.
baeseongsu.github.io
pl의 기본적인 틀에 맞춰 KoBART 모델은 정교하게 짜여져 있었습니다pl의 핵심 요소는 LightningModule 클래스와 Trainer 클래스에 있는데,
KoBART의 다양한 클래스 중에서 LightningModule을 내포하는 Base 클래스와 학습 환경과 파라미터를 내포하는 KoBARTConditionalGeneration 클래스가 주 요소라는 것을 파악했습니다
기존에는, 아래 pl 공식문서를 기반으로 pl의 load_from_checkpoint 함수를 이용했습니다
Checkpointing — PyTorch Lightning 1.7.1 documentation
Shortcuts
pytorch-lightning.readthedocs.io
얘가 된다고 해서 해봤는데,, 잘 안되더라구요ㅠ
2. 학습 모델 불러오기 및 테스트 코드 작성
AttributeError: 'collections.OrderedDict' object has no attribute 'eval'
I have a model file which looks like this OrderedDict([('inp.conv1.conv.weight', (0 ,0 ,0 ,.,.) = -1.5073e-01 6.4760e-02 1.9156e-01 1.2175e-01 3.5886e-02 1.39...
stackoverflow.com
다양하게 만난 에러를 수정하며 아래 테스트 코드를 완성시켰습니다
import numpy as np
import pandas as pd
import torch
from kobart_chit_chat import *
import yaml
filename = 'logs/kobart_chitchat-last.ckpt'
hparams = 'logs/tb_logs/default/version_17/hparams.yaml'
with open(hparams) as f:
h = yaml.load(f, Loader=yaml.FullLoader)
checkpoint = torch.load(filename)
model = KoBARTConditionalGeneration(h)
model.load_state_dict(checkpoint['state_dict'])
model.model.eval()
accuracy = 0
test_file = pd.read_csv('Chatbot_data/test.csv')
for i in range(len(test_file)):
q = test_file['Q'].iloc[i]
a = test_file['A'].iloc[i]
result = model.chat(q).replace('<usr>','')
if result.strip() == a.strip():
accuracy += 1
else:
print(f'질문: {q}')
print(f'대답(예측): {result.strip()}')
print(f'대답(정답): {a.strip()}')
print()
print('Accuracy: ', accuracy / len(test_file))
일단 hparams의 존재를 알고 이를 불러왔습니다.
train 모델에서 따로 hparams.yaml 파일을 저장하게 되는데,
저는 이 yaml 파일을 불러오는 과정에서 처음에 에러가 발생했었습니다
그래서 yaml파일을 직접 열어보니, 형식이 살짝 이상한 부분이 있었습니다
hparams: !!python./object:argparse.Namespace
라고 작성된 부분에서 !!를 지우고 아래 들여쓰기를 제거한 후
yaml.load 를 통해 해당 파일을 불러왔습니다
사전학습모델은 KoBARTConditionalGeneration에 hparams를 인자로 넣으면서 불러왔고,
load_from_checkpoint가 아닌 load_state_dict를 통해 ckpt 형식의 모델을 불러왔습니다.
(이 과정에서 torch.load(~~).key() 를 통해 하나하나 딕셔너리의 값들을 보며 깨우쳤었습니다..)
3. 분석 지표 성능 개선
제 데이터 기준으로 위 테스트 파일을 실행시켰을 때 정확도는 56%가 나옵니다.
그러나 위와 같이 조건문을 통해 예측에 실패한 데이터를 출력하여 검증해본 결과
같은 대답 형식인데 예측 대답의 경우 문장이 중간에서 끊기는 현상이 발생하여 이를 틀렸다고 잡는 경우가 있었습니다.
train 코드를 보면 chat에서 max_length를 hparams에서 수정해주어야 하는 것 같습니다.
hparams.yaml에서 max_length를 기존 36으로 되어있는 것을 180으로 수정해준 결과
정확도 56%에서 62%로 증가하였고,
분명 대답은 같은데 다르게 나오는 것들을 잡아보기 위해서 조건문의 형태를 아래와 같이 변형할 수도 있습니다
(아래와 같이 수정하면 정확도가 76%까지 올라갑니다. 하지만 결과의 신뢰성은 떨어지게 됩니다.)
if result.strip()[:10] == a.strip()[:10] or result.strip()[-10:] == a.strip()[-10:]:
accuracy += 1
else:
print(f'질문: {q}')
print(f'대답(예측): {result.strip()}')
print(f'대답(정답): {a.strip()}')
print()
이렇게 해본 이유가,,
일단 먼저 학습 시에 토크나이저가 bad word을 수정해주어 변형된 문장이 나오는 경우가 발생하는 것 같이 보입니다.
뜯어봐야 알겠지만, else에서 나온 출력 결과 일부를 보면


뭐 이런것들,, 기존 내 질의응답 데이터에는 없던 조사, 부사 등이 model을 돌리면 일부는 생기곤 합니다.
아마 KoBART의 pre-train된 모델은 seq2seq 구조로 설계되어 있고,
인코딩과 더불어 디코딩을 통해 masking 방법으로 학습을 시켰기에
기존 문자열과 다르게 새롭게 디코딩된 문자열이 추가되는 것 같습니다.
그리고 그와 더불어서,

chat 함수에서 transformer 라이브러리의 모델 생성 기능 때문인지,
num_beams라는 빔 서치에 의하여 n번만큼 반복하여 최대 확률을 내는 단어 시퀀스를 출력하게 됩니다
그래서 False Positive로 빠져 정확도에 영향을 미치는 것을 볼 수 있죠ㅠ
그렇게 위 코드로 조금은 얍삽하게 이들까지 TP로 봐버리면, 정확도는 어느정도 잡히겠지만
신뢰성 부분에서 유의미한 결과가 아닐 것이라고 생각하여 파라미터를 조금 뜯어보았습니다.
그렇게 잔 오류들을 없애기 위해, kobart_chit_chat.py에서 chat 함수를 아래와 같이 수정했습니다
def chat(self, text):
input_ids = [self.tokenizer.bos_token_id] + self.tokenizer.encode(text) + [self.tokenizer.eos_token_id]
res_ids = self.model.generate(torch.tensor([input_ids]),
max_length=self.hparams.max_seq_len,
num_beams=1,
no_repeat_ngram_size=2,
eos_token_id=self.tokenizer.eos_token_id,
bad_words_ids=[[self.tokenizer.unk_token_id]])
a = self.tokenizer.batch_decode(res_ids.tolist())[0]
return a.replace('<s>', '').replace('</s>', '')- 참고 : https://ratsgo.github.io/nlpbook/docs/generation/inference1/
빔서치 탐색을 하는 횟수를 최소화하여 매 순간이 최선의 선택이게끔 했고, 그 첫번째 최선의 선택이 기존 ANSWER 데이터일 것이라고 생각했습니다. 그래서 num_beams를 1로 두었습니다
기존에 num_beams를 이리저리 조절해보다가 설정한 것인데, 반복되는 n-gram의 등장 횟수를 줄이기 위해 no_repeat_ngram_size를 2로 설정하여 최대 반복 횟수를 2회로 설정하였습니다
그리고 bad_words_ids 파라미터를 없애면 문장이 변화하는게 방지되지 않을까? 했는데,
없앤 상태로 학습을 해보니 결과에 변함이 없어 그대로 냅두었습니다.
하지만 눈에띄는 변화는 나타나지 않습니다. 정확도 또한 62%에서 63%로 아주 미미하게 증가하였습니다,, ㅠ
파라미터 관련 분석을 조금 더 한 뒤에 경험적으로 조절해가며 값을 수정해주어야 할 것 같습니다.
4. 시간 성능 측정
속도 측정은 pytorch의 profiler 라이브러리를 이용하여 측정하였습니다.
(참고 : https://jh-bk.tistory.com/20)
import torch.autograd.profiler as profiler
with profiler.profile(with_stack=True, use_cuda=True, profile_memory=True) as prof:
out = model.chat(q)
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))
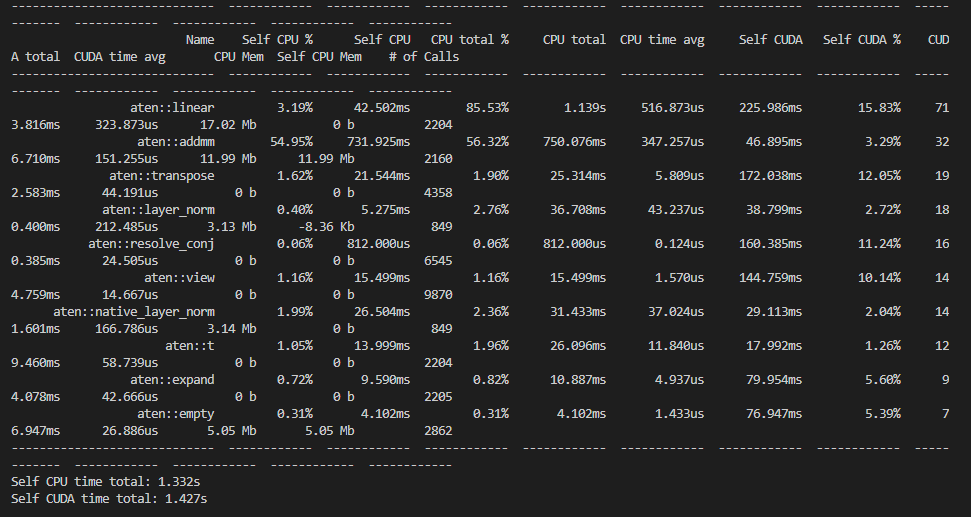
위 프로파일러 라이브러리를 이용하게 되면 함수의 호출 수, 소모 시간 등 CPU와 GPU에서 얼마나 연산 용량을 차지하는지를 한 눈에 정리해주는 표를 출력해줍니다.
따라서 파이토치 모델의 각 연산에 대해 시간과 메모리 소모량을 한 번에 측정할 수 있다고 합니다.
저같은 경우 GPU와 cuda device를 사용하기 때문에 use_cuda=True 처리를 해주었습니다
각 모델 연산당 약 1초 이상의 시간이 걸렸던 것을 확인할 수 있네요.
특히 aten - linear, addmm, transpose 등에서 많은 연산 비중을 차지하는 것을 보면,
행렬 처리 관련하여 많은 연산 처리가 일어났음을 볼 수 있습니다.
이렇게 KoBART 학습을 마치고 테스트와 성능 측정을 해보았는데,
저는 이와 병행하여 KoBERT 모델을 가지고도 함께 비교해보았습니다
제가 활용한 데이터 기준으로, 총 크기는 500이고
train / validation / test 를 각 5:3:2 비율로 나누어 동일하게 측정하였을 때
결론은 KoBERT의 성능이 더 우수했습니다
학습 속도의 경우 KoBERT는 약 30시간, KoBART는 약 15분으로 압도적인 차이가 있기는 하였지만
메모리 사용량과 속도에 있어서는 KoBERT가 한참 우세했으며, 정확도 또한 KoBERT가 조금 높았었습니다.
KoBERT의 메모리 사용 시간은 GPU 기준 50~80ms을 맴돌았으나
KoBART는 1s 단위로 넘어갔습니다. 10배 이상 차이가 났네요.
이는 테스트를 하는 과정에서 눈에 보기에도 느껴지는 차이였습니다.
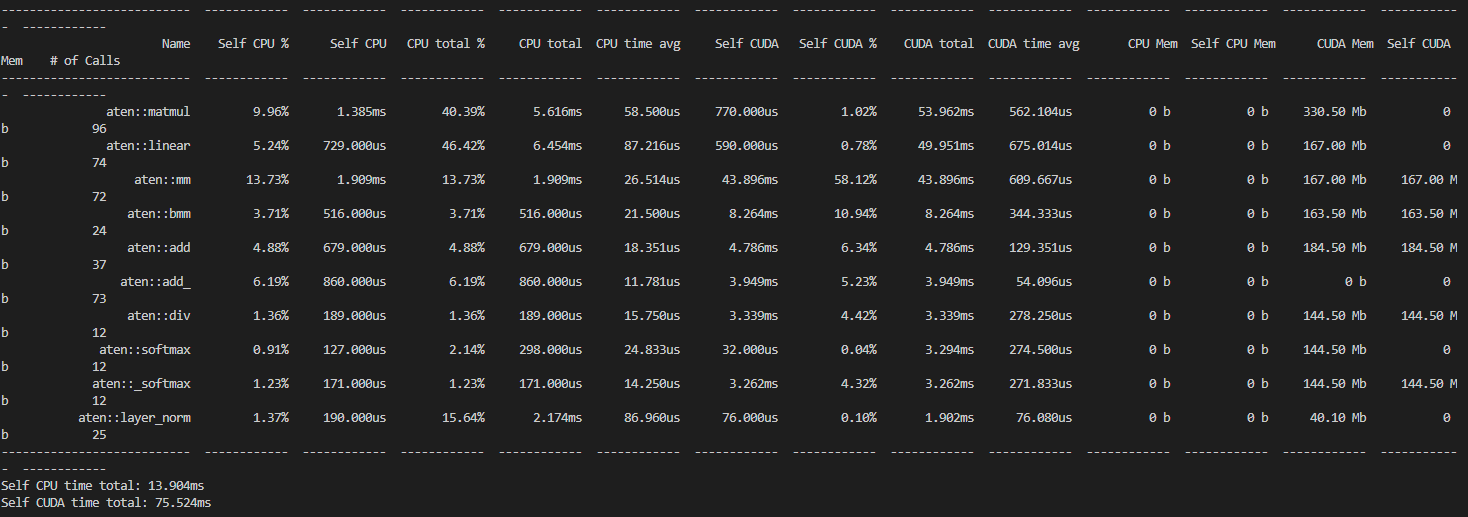
또한 KoBERT의 test set에 대한 정확도는 77%, KoBART는 63%가 나왔습니다.
파라미터 값과 데이터의 크기에 따라 달라지는 값들이기는 합니다.
실제로 KoBART는 validation set이 있었고 KoBERT는 없었기에
학습시킨 데이터 양 기준으로는 KoBERT가 더 많아 정확도에 차이가 발생했기도 합니다.
총 데이터 개수가 얼마 안되기도 했어서, 개인적인 생각으로는 데이터 양을 늘리고
디코딩 방식에 파라미터를 수정하여 출력되는 문장이 최대한 원본 형태를 유지하도록 한다면
KoBART의 정확도가 급격히 증가하지 않을까 생각합니다
'Programming > NLP' 카테고리의 다른 글
| [NLP] KoBART Chit-Chat bot(챗봇) 모델링 및 학습 과정 (0) | 2022.08.11 |
|---|
