
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 서버
- FastAPI
- keras
- Linux
- jquery
- 모델적응
- Model Adaptations
- KoBERT
- Custom Classes
- Kaggle
- Django
- AWS
- KoBART
- ubuntu
- 가장쉽게배우는머신러닝
- 스파르타코딩클럽
- mnist
- 4주차
- Google Speech To Text
- EC2
- Phrase Sets
- ajax
- html
- model
- Flask
- 과일종류예측
- Transfer_Learning
- UbuntuServer
- Ubuntu2004
- 우분투2004
- Today
- Total
영웅은 죽지 않는다
머신러닝 때려 부수기 - 캐글 데이터를 이용한 선형 회귀 (Linear Regression) 본문
머신러닝 때려 부수기 - 캐글 데이터를 이용한 선형 회귀 (Linear Regression)
YoungWoong Park 2021. 7. 23. 15:13선형회귀(Linear Regression)란
머신러닝의 종류에는 무엇이 있고.. 이런 이야기는 건너 뛰고 바로 선형 회귀로 건너가 봅시다.
선형 회귀는 말 그대로 가정을 선형으로 표현하여 예측할 수 있는 형태를 말합니다.
예를 들어, '시험 전 날 마신 커피 잔 수에 따라 시험 점수를 예측할 수 있을까?'라는 가정에 대해,

실험을 통해 다음과 같은 결과를 얻을 수 있었고 이를 그래프로 표시하면 아래와 같이 나옵니다.

우리는 이 그래프를 보고, 임의의 직선 1개로 이 그래프를 비슷하게 표현할 수 있다고 가설을 세울 수 있습니다. 이 선형 모델은 수식으로 H(x) = W x + b 와 같이 표현할 수 있습니다.
여기서 마신 커피 수에 따른 정확한 시험 점수를 예측하기 위해서는 우리가 만든 직선(가설)과 점(정답)의 거리가 가까워지도록 해야 합니다. 이는 Mean Squared Error(MSE)를 줄이는 것과 의미가 같습니다.

여기서 H(x)는 우리가 가정한 직선, y는 정답 포인트라고 했을 때 이 둘 사이의 거리가 최소가 되었을 때 이 모델은 잘 학습되었다고 말할 수 있습니다.
- H(x) : 우리가 임의로 만든 직선, 가설(Hypothesis)
- Cost : 손실 함수(Cost or Loss function)
다중 선형 회귀 (Multi-variable Linear Regreesion)
이는 선형 회귀와는 다르게 입력 변수가 여러 개인 회귀 방법입니다. 예를 들어,

위 선형회귀에서는 입력 변수 x 값이 커피 잔 수 하나였으나 다중 선형 회귀에서는 게임 플레이 시간까지 추가된 형태라고 볼 수 있습니다. 그렇기에 가설과 손실 함수의 형태가 다음과 같습니다.

경사 하강법 (Gradient descent method)
위에서 얘기한 손실 함수(Cost or Loss function)의 형태가 다음과 같다고 가정해봅시다 !

(출처: https://towardsdatascience.com/using-machine-learning-to-predict-fitbit-sleep-scores-496a7d9ec48)
우리의 목표는 손실 함수를 최소화하는 것이기에 그 방법은 이 그래프를 따라 점점 아래로 내려가는 형태가 될 것입니다. 그 최소화하는 방법 중 가장 대표적인 것이 경사 하강법입니다.
처음에 랜덤으로 한 점으로 시작했다가, 좌우로 조금씩 그리고 한 번씩 움직이면서 이전 값보다 작아지는지를 관찰합니다. 한 칸씩 전진하는 단위를 Learning rate(lr)이라고 부르며, 그래프의 최소점에 도달하게 되면 학습을 종료하게 됩니다.
여기서 중요한 점은, 우리가 만든 머신러닝 모델이 학습을 잘 하기 위해서는 적당한 lr을 찾는 노가다가 필수라는 것입니다.

(출처: https://towardsdatascience.com/using-machine-learning-to-predict-fitbit-sleep-scores-496a7d9ec48)
위 그래프에서,
1. Learning rate가 작다면 : 초기 위치로부터 최소점을 찾는데까지 많은 시간이 걸립니다.
2. Learning rate가 크다면 : 우리가 찾으려는 최소값을 지나치고 검은 점은 계속 진동하다가, 최악의 경우 발산하게 될 수도 있습니다.(Overshooting)
- 복잡한 가설을 세울 경우 손실 함수의 형태

(출처: https://regenerativetoday.com/logistic-regression-with-python-and-scikit-learn/)
우리의 목표는 이 손실 함수의 최소점인 Global cost minimum을 찾는 것이지만, 한 칸씩 움직이는 Learning rate를 잘못 설정할 경우 Local cost minimum에 빠질 가능성이 높아집니다.
cost가 높아지게 되면 우리가 만든 모델의 정확도가 낮아지게 되므로, 최대한 Global minimum을 찾기 위해 좋은 가설과 좋은 손실 함수를 만들어서 기계가 잘 학습할 수 있도록 만들어야 합니다.
데이터셋 분할

(출처: https://3months.tistory.com/118)
1. Training set (학습 데이터셋) = 교과서
머신러닝 모델을 학습시키는 용도로 사용하며, 보통 80% 정도의 비율을 갖습니다.
2. Validation set (검증 데이터셋) = 모의고사
머신러닝 모델의 성능을 검증하고 튜닝하는 지표의 용도로 사용합니다. 정답 라벨이 주어지고 학습 단계에서 사용하기는 하지만, 모델의 성능에 영향을 미치지는 않습니다.
3. Test set (평가 데이터셋) = 수능
정답 라벨이 없는 실제 환경에서의 평가 데이터셋입니다.
아래에서는 Colab을 통해 Kaggle 데이터셋을 긁어온 후 Validation set이 포함된 데이터셋을 구축하여 학습하고 평가할 예정입니다.
Kaggle에서 데이터셋 다운로드하기
캐글에서 데이터셋을 다운로드하는 방법에는 여러가지가 있지만, 우리는 그 중에서도 os 브라우저로 API를 복사해 온 후 실행하는 방법을 이용하겠습니다.
1. 먼저 캐글에 로그인 한 후 내 프로필을 클릭하여 Account 탭을 클릭합니다.

2. API - Create New API Token을 클릭하여 kaggle.json 파일을 다운로드 받습니다.

3. 다운로드한 파일을 브라우저에서 파일을 열어 username과 key를 복사합니다.

4. 환경변수를 지정하여 자신의 username과 key를 입력합니다.
import os
os.environ['KAGGLE_USERNAME'] = '[내_캐글_username]' # username
os.environ['KAGGLE_KEY'] = '[내_캐글_key]' # key5. 원하는 데이터셋의 API를 복사해 와 실행합니다.
여기서 이용해 볼 캐글 데이터셋은 광고 데이터셋으로, 해당 페이지에서 Copy API command를 통해 API 주소를 복사할 수 있습니다.
!kaggle datasets download -d ashydv/advertising-dataset6. 위 코드까지 입력을 완료했다면 코랩 내 파일에 데이터셋 압축폴더가 추가된 것을 확인할 수 있습니다. 다음 코드를 입력하여 데이터셋 폴더의 압축을 풀어줍니다.
!unzip /content/advertising-dataset.zip
자 여기까지가 API 데이터셋을 코드를 통해 불러오는 방법이었습니다. 이제 본격적으로 데이터를 분석해보는 과정을 진행하겠습니다 ! ! !
데이터 분석하기 - 선형 회귀
- 필요한 라이브러리 import
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split선형회귀를 하는 모듈 중 대표적으로 쓰이는 것은 tensorflow와 tensorflow 내장모듈인 keras가 있습니다. 우리는 이 중에서도 tensorflow에서 권장하는 모듈인 keras를 이용하여 선형회귀를 진행하겠습니다 !
- 데이터셋을 불러와 형태 확인하기
df = pd.read_csv('advertising.csv')
df.head(5)
csv 형태의 파일을 읽어와 데이터의 형태를 확인합니다.
추가적으로 df.shape 를 통해 데이터셋의 크기가 (200,4) 인 것을 확인할 수 있습니다.
- 데이터셋 살짝 살펴보기
sns.pairplot(df, x_vars=['TV', 'Newspaper', 'Radio'], y_vars=['Sales'], height=4)
seaborn을 통해 각 데이터별 분포를 시각화 했을 때의 모습입니다. 이로써 데이터프레임 내에 'TV' 데이터가 어느정도 선형을 이루고 있을 것이라 짐작할 수 있습니다.
- 데이터셋 가공하기
x_data = np.array(df[['TV']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
print(x_data.shape)
print(y_data.shape)x_data는 (200,1), y_data는 (200,)의 결과창이 나오는 것을 확인할 수 있습니다. 이 두 데이터들을 선형으로 나타내기 위해서 같은 크기의 형태로 묶어줘야 하기 때문에, 이를 reshape하는 과정이 필요합니다.
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)이로써 두 데이터 모두 (200,1) 크기로 맞추어졌음을 알 수 있습니다.
- 데이터셋을 학습 데이터와 검증 데이터로 분할하기
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)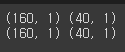
( 여기서는 편의를 위해 test set을 나누지 않고 train set과 validation set으로만 나누었습니다. 실무에서는 꼭 test set으로도 나누는 과정을 거쳐야 합니다 ! )
- 학습시키기
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)model에 compile할 때 loss function을 Mean Squared Error(MSE) 방법을 이용하고, optimizer를 Adam으로, Learning rate를 0.1로 설정했습니다. 또한 epochs를 100으로 설정했기에 검증하는 과정을 100번을 반복학습하여 loss값과 val_loss값을 나타냅니다.


결과창을 보면 Epoch를 반복하면 반복할 수록 loss의 값과 val_loss값이 감소하는 것을 확인할 수 있는데, 이는 학습이 잘 되고 있음을 암시할 수 있습니다.
- 검증 데이터로 예측하기
학습을 잘 마쳤다면 validation set으로 모델을 예측하는 y_predict 값을 만들어 봅니다.
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val)
plt.scatter(x_val, y_pred, color='r')
plt.show()
위 그래프와 같이 y_pred (예측)값은 선형을 이루는 형태의 값이 나오게 되며, 이로써 학습이 잘 되었고 검증 또한 잘 되었다고 할 수 있습니다.
데이터 분석하기 - 다중 선형 회귀
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('advertising.csv')
df.head(5)
import 하고 csv 파일을 불러오는 것까지는 위와 동일합니다.
x_data = np.array(df[['TV', 'Newspaper', 'Radio']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
x_data = x_data.reshape((-1, 3))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)하지만 다중 선형 회귀에서는 numpy array로 여러 개의 입력 변수를 설정합니다. 그렇기 때문에 reshape하는 과정에서 column의 수가 증가하며 위 코드를 입력했을 때 (200,3)과 (200,1)이 출력되는 것을 알 수 있습니다.
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data,
test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
))
test_size를 20%로 설정했기에 x_train은 (160,3), x_val은 (40,3)의 크기를 갖고 있으며
y_train은 (160,1), y_val은 (40,1)의 크기를 가지게 됩니다.
위 선형 회귀 코드와 동일하게 코드를 입력하여 학습을 시키면,


이 역시 Epoch를 반복할 수록 loss값과 val_loss값이 감소하는 형태로, 학습이 잘 되었다는 것을 알 수 있습니다.
y_pred = model.predict(x_val)y_pred값을 생성한 후 각각의 val값과 pred값을 비교할 수 있도록 시각화 하는 과정입니다.
- 'TV' 데이터 예측 그래프
plt.scatter(x_val[:, 0], y_val)
plt.scatter(x_val[:, 0], y_pred, color='r')
plt.show()
오른쪽 그래프와 같이 어느 정도 선형을 띄는 형태로 잘 예측한다고 볼 수 있습니다.
- 'Newspaper' 데이터 예측 그래프
plt.scatter(x_val[:, 1], y_val)
plt.scatter(x_val[:, 1], y_pred, color='r')
plt.show()
이는 그렇다 할 선형성을 보이지 않고 있습니다. 예측으로만 보았을 때는 어느 정도 맞아보이기는 하지만, 연관관계가 애초에 없었기에 랜덤성을 띄는 것 같아 보입니다.
- 'Radio' 데이터 예측 그래프
plt.scatter(x_val[:, 2], y_val)
plt.scatter(x_val[:, 2], y_pred, color='r')
plt.show()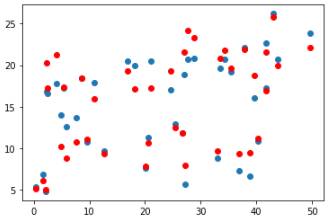
이 또한 Newspaper 데이터와 같이 선형성을 띄지 않고 있으며 특별한 연관관계가 없어 예측을 잘 한 것인지 직관적으로 확인하기 힘듭니다.
'Programming > Machine Learning' 카테고리의 다른 글
| [Google Cloud] Speech-To-Text의 모델 적응 기능 활용해 STT 성능 높이기 (0) | 2022.10.27 |
|---|---|
| 딥러닝 때려 부수기 - 전이 학습(TL), 캐글 데이터를 이용한 과일 종류 예측 모델 (0) | 2021.08.19 |
| 딥러닝 때려 부수기 - 합성곱 신경망(CNN), 캐글 데이터를 이용한 수화 알파벳(MNIST) 분류 모델 (0) | 2021.08.18 |
| 딥러닝 때려 부수기 - 신경망 개념&스킬, 캐글 데이터를 이용한 XOR문제 해결 (0) | 2021.08.14 |
| 머신러닝 때려 부수기 - 캐글 데이터를 이용한 논리 회귀(Logistic Regression), 전처리(Preprocessing) (0) | 2021.08.01 |



