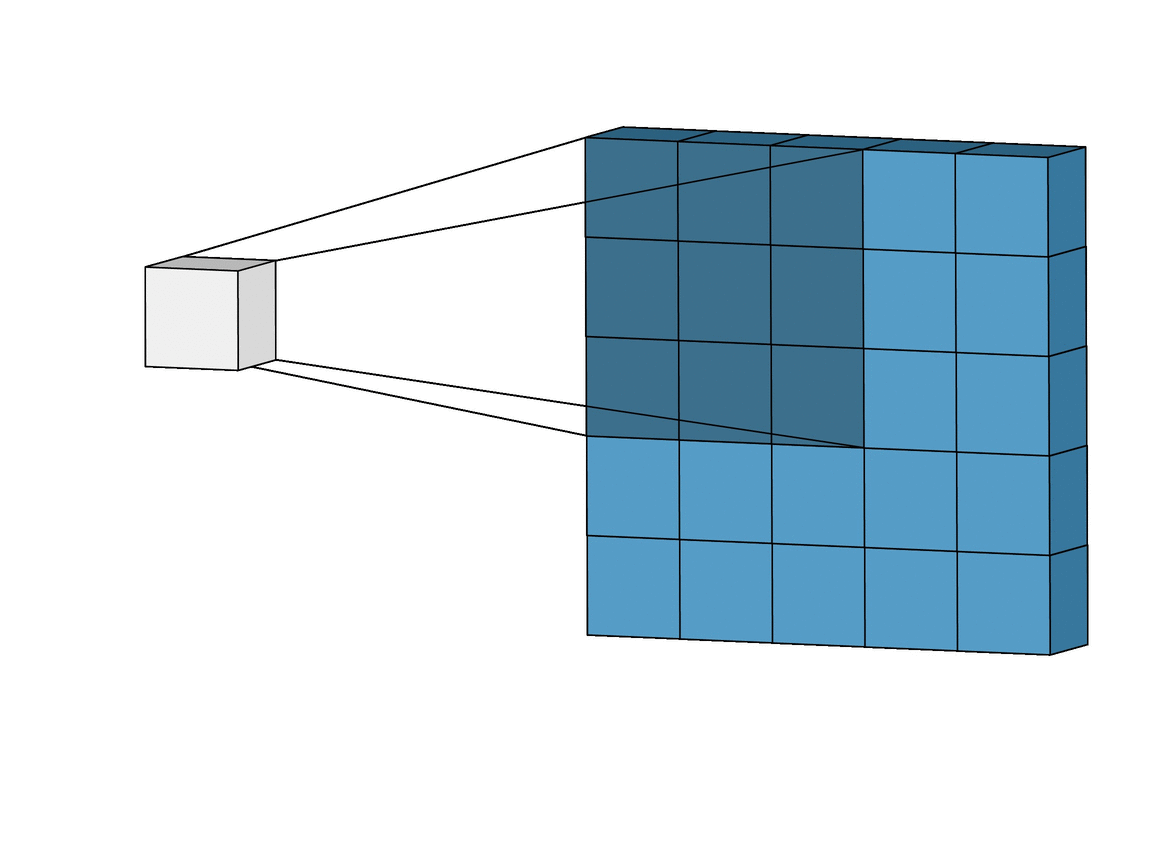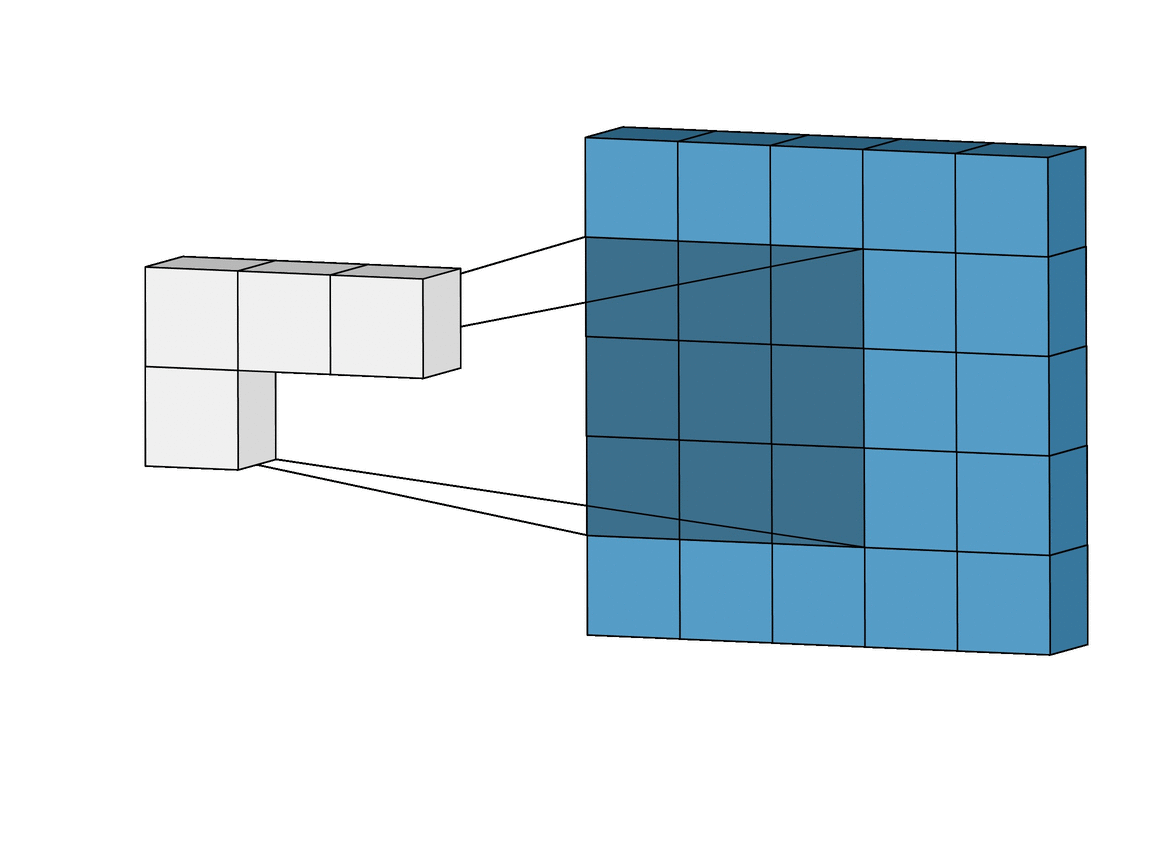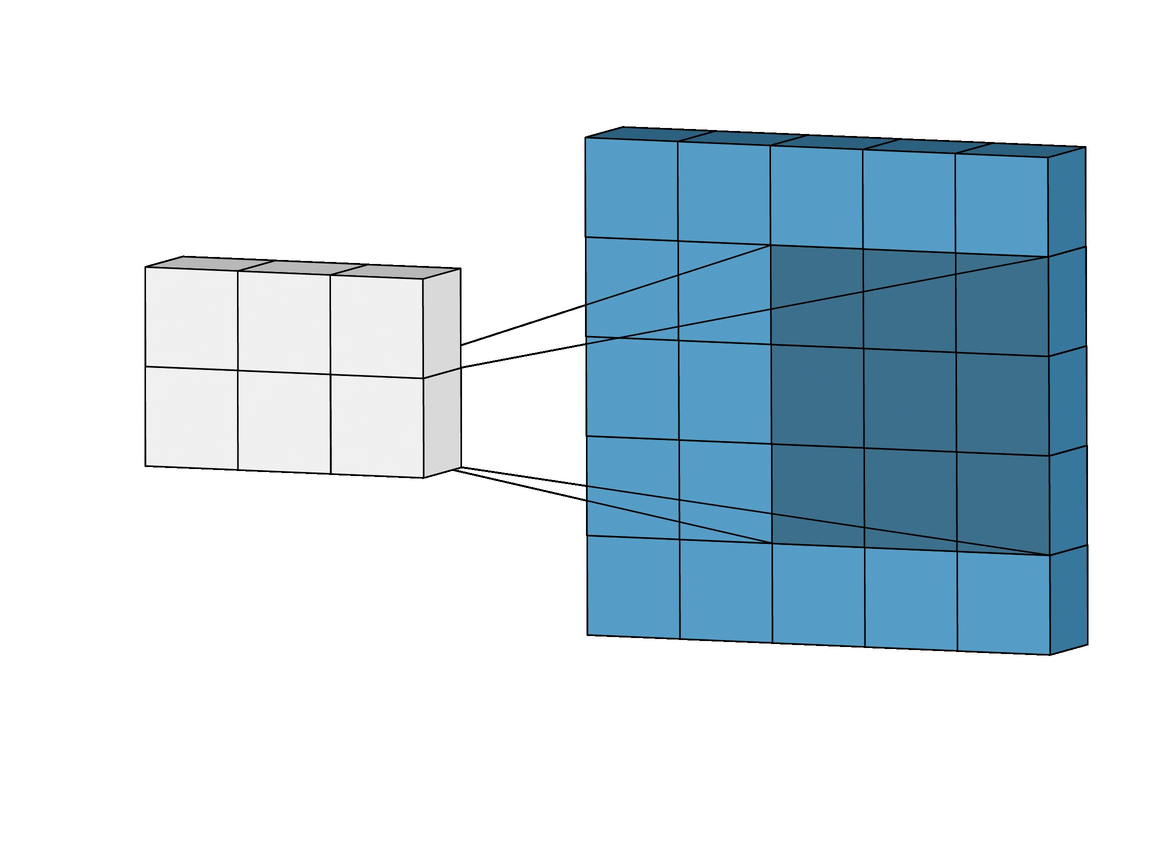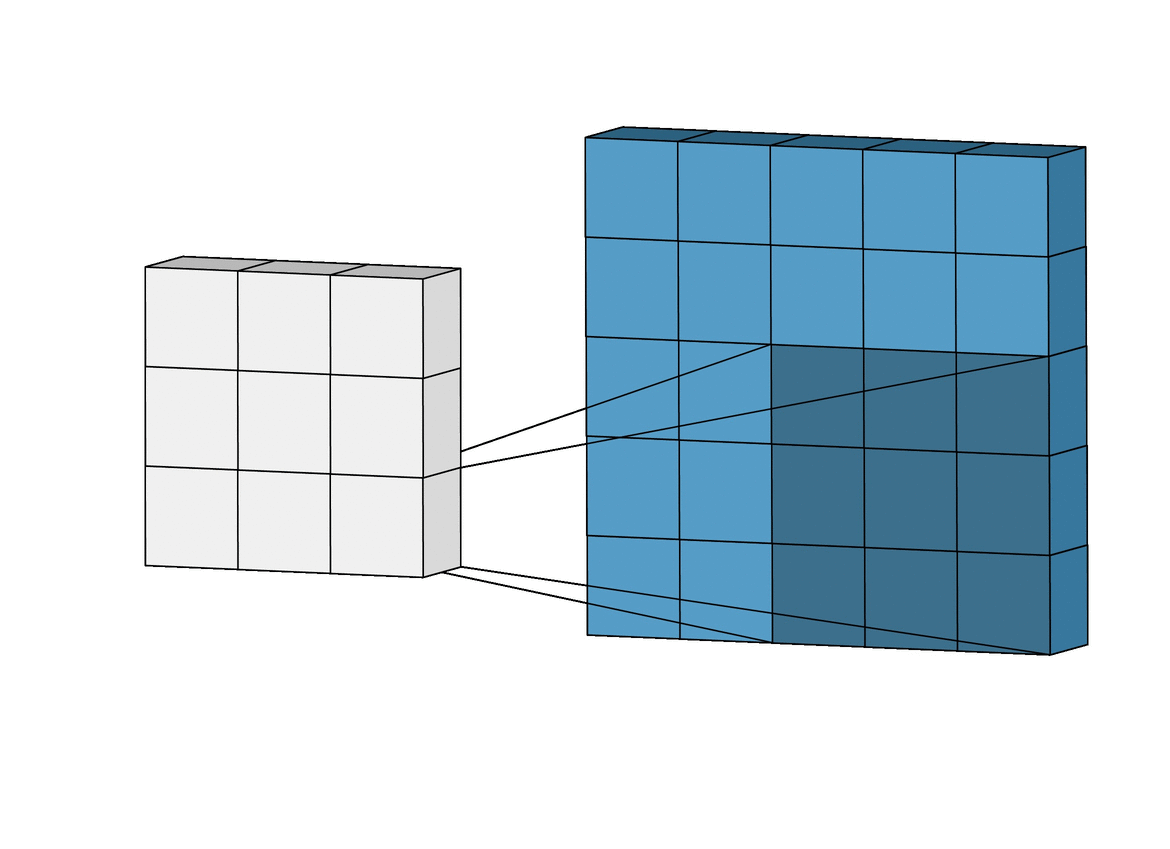
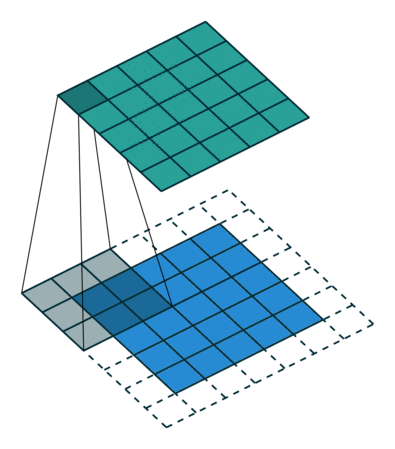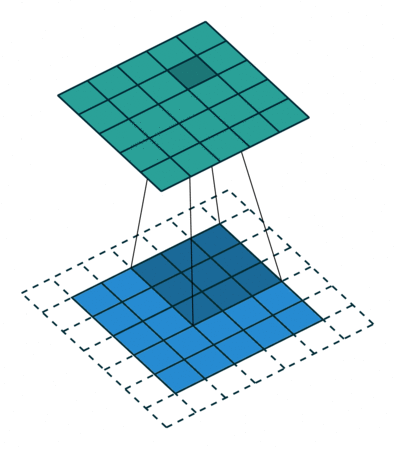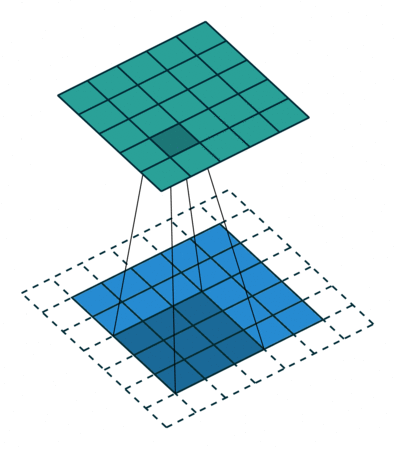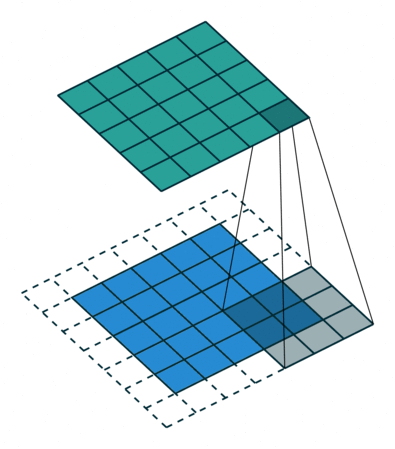
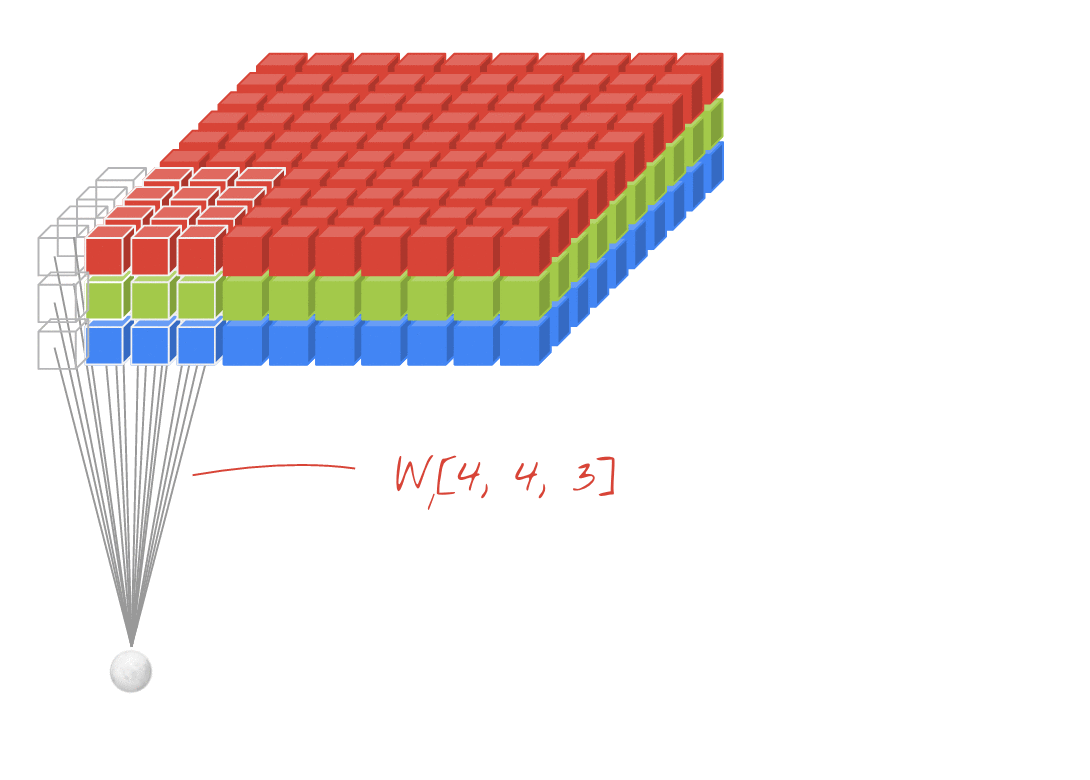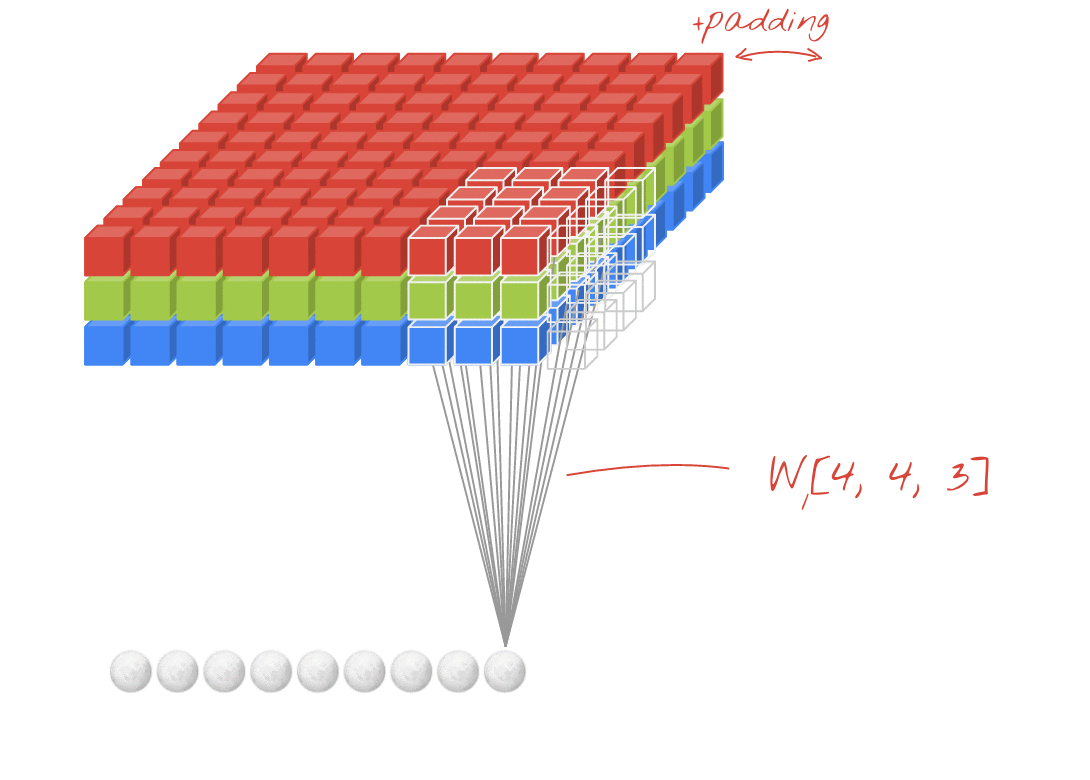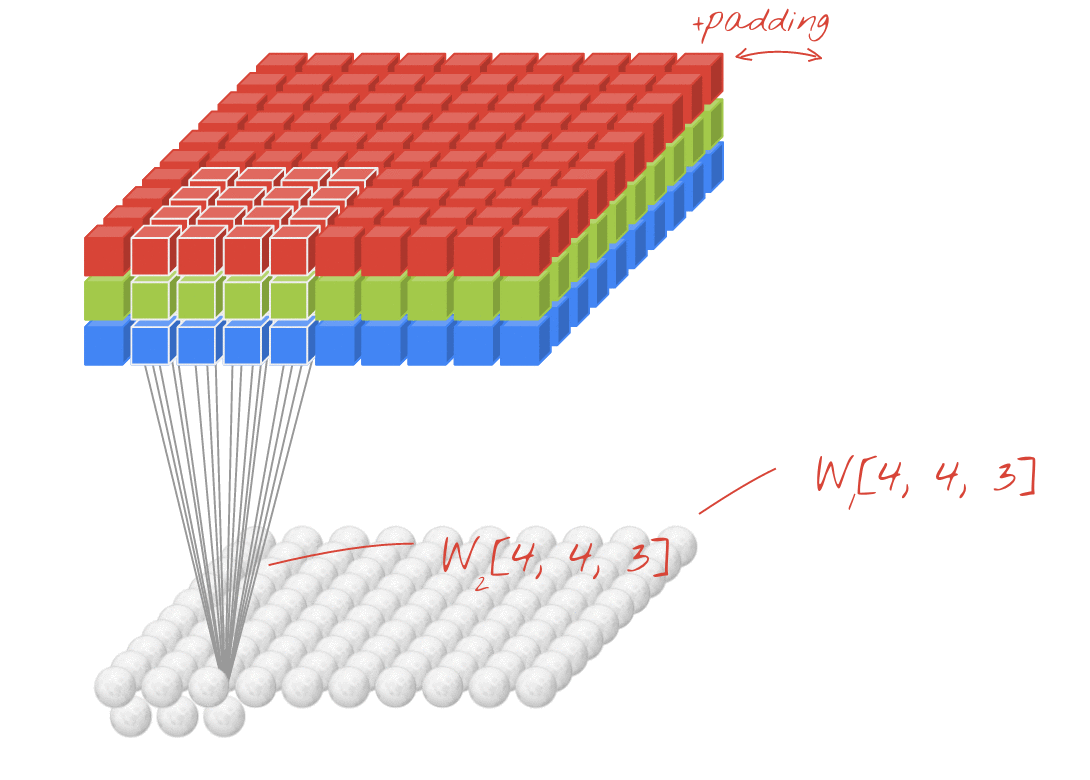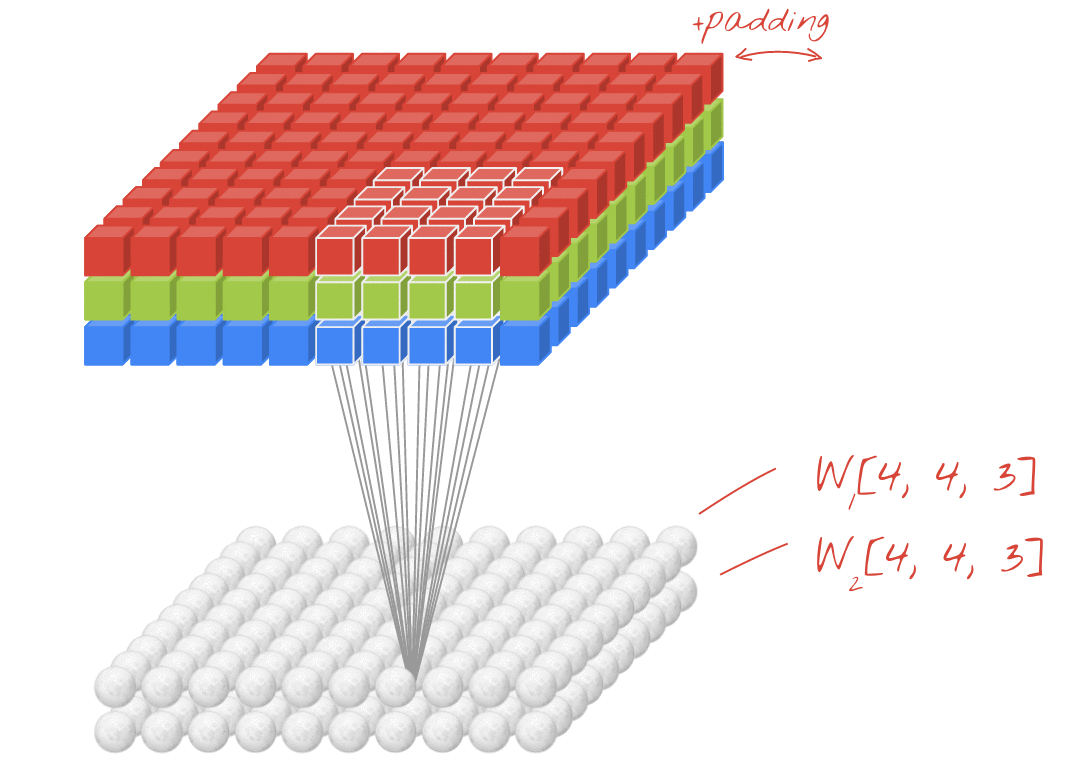
합성곱 계층 + 활성화 함수 + 풀링을 반복하며 점점 작아지지만, 핵심적인 특성들을 뽑아내게 되고, 풀링 계층(Pooling Layer)은 Feature Map의 중요 부분을 추출하여 저장하는 역할을 하게 됩니다.
풀링 계층에서 Pooling의 방법에 따라 Max Pooling과 Average Pooling 두 가지가 있는데, 말 그대로 최대값으로 하느냐, 평균값으로 하느냐로 나뉩니다.출처: https://towardsdatascience.com/beginners-guide-to-understanding-convolutional-neural-networks-ae9ed58bb17d
풀링 계층을 지나 완전연결 계층(Dense Layer, Fully Connected)와 연결이 되어야 하나, 풀링을 통과한 Feature Map은 2차원이고 Dense Layer는 1차원이기에 연산이 불가능합니다. 따라서 평탄화 계층(Flatten Layer)를 사용해 2차원을 1차원으로 펼치는 작업을 진행해야 합니다.
평탄화 계층을 통과하여 행렬 곱셈을 한 후, 동일하게 Dense(Fully Connected) + Activation function의 반복을 통해 노드의 개수를 점점 축소시키다가, 마지막에 Softmax 활성화 함수를 통과하고 출력층으로 결과를 나타내게 됩니다.
CNN의 활용
물체 인식(Object Detection) : Computer Vision에서 가장 중요한 기술이며, 이미지에서 정확히 사물 또는 사람을 인식하는 것을 뜻합니다.
YOLO (You Only Look Once) : 현재 V5 버전까지 나왔으며, 속도가 빠르고 정확도가 높은 CV 알고리즘 입니다.
이미지 분할(Segmentation) : 각 Object에 속한 픽셀들을 분리하는 것을 나타냅니다. 이는 나누는 기준이 디테일 할수록 정교화된 성능을 가져야 합니다. 특정 기준(Class)에 따라 분리하거나 인물을 Focusing할 때 사용됩니다.
CNN의 종류
AlexNet (2012) : 컴퓨터 비전 분야의 큰 대회인 ILSVRC에서 2012년도에 우승한 모델입니다. AlexNet은 의미있는 성능을 낸 첫 번째 합성곱 신경망이고, Dropout과 Image Augmentation 기법을 효과적으로 적용한 딥러닝 기법입니다.
VGGNet (2014) : 이는 parameter의 개수가 많고 모델의 깊이가 deep한 기술로 유명합니다. 또한 전이 학습 등을 통해서 가장 먼저 테스트하는 모델로도 잘 알려져 있습니다. 간단한 방법론으로 좋은 성적을 낼 수 있습니다.
GoogLeNet(=Inception V3) (2015) : 위에서 언급한 LeCun 교수가 구글에서 개발한 합성곱 신경망 구조입니다. 이는 VGGNet보다 구조가 복잡하여 널리 쓰이진 않았지만, 하나의 계층에서도 다양한 종류의 filter, pooling을 도입함으로써 개별 계층을 두텁게 확장시킬 수 있다는 아이디어인 Inception module 구조 면에서 주목을 받았습니다. 이 1*1 합성곱 계층 아이디어로 조금 더 다양한 특성을 모델이 찾을 수 있게 하고, 신경망이 깊어졌음에도 사용된 parameter를 절반까지 줄일 수 있었습니다.
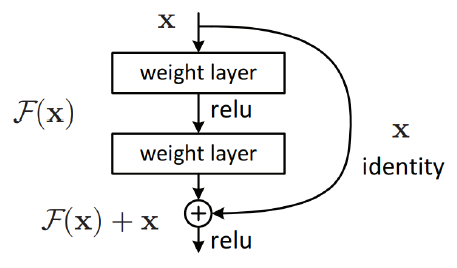
ResNet (2015) : AlexNet이 제안된 이후로 합성곱 신경망의 계층은 점점 깊어졌는데, 층이 깊어질수록 역전파(Backpropagation)의 기울기가 점점 사라져서 학습이 잘 되지 않는 문제가 발생했습니다. 이 문제점을 해결하고자 ResNet은 기울기가 잘 흐를 수 있도록 지름길(Shortcut)을 만들어주는 Residual block을 제시했습니다.
오른쪽 그림에서 F(x) = y - x 꼴로 표현해 입력과 출력 간의 학습 차이를 학습하도록 설계하였으며, 예를 들어 위조 지폐범은 더욱 정밀하게 지폐를 위조하고 경찰은 더욱 정밀하게 위조된 지폐를 찾아내는 작업에 비유할 수 있습니다. 이는 합성곱 신경망 모델 성능에 큰 영향을 끼치게 되었습니다.
CNN을 이용한 Sign Language MNIST(수화 알파벳)
지난 주차에서 수화 MNIST를 단순 딥러닝 모델(MLP)을 이용해 분류해본 것과 다르게, 이번에는 CNN을 이용해 분류해 보겠습니다.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
여기서 data augmentation을 위해 keras에서 ImageDataGenerator 모듈을 추가로 가져옵니다.
하지만 6이라는 값을 컴퓨터가 이해하기 힘들기 때문에, One-Hot-Encoding을 진행하여 크기가 1에서 24로 증가하였습니다.
( 6 ㅡ> [0,0,0,0,0,1,0,0,0,...,0] )
- 전처리 : 일반화하기
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
)
# generator 과정
train_datagen = train_image_datagen.flow(
x=x_train,
y=y_train,
batch_size=256,
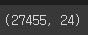
shuffle=True # 27,455개의 데이터 순서를 섞어줌
)
test_image_datagen = ImageDataGenerator(
rescale=1./255
)
test_datagen = test_image_datagen.flow(
x=x_test,
y=y_test,
batch_size=256,
shuffle=False # test data에서는 랜덤성을 주지 않는다.
)
index = 1
preview_img = train_datagen.__getitem__(0)[0][index]
preview_label = train_datagen.__getitem__(0)[1][index]
plt.imshow(preview_img.reshape((28, 28)))
plt.title(str(preview_label))
plt.show()
이미지 데이터는 픽셀이 0~255 사이의 정수로 되어 있기에, 이것을 255로 나누어 0~1 사이의 소수점 데이터(float32)로 바꾸고 일반화를 시키는 과정이 필요합니다. 여기서는 MLP 방법때와는 다르게 ImageDataGenerator()를 사용해 일반화를 해보았습니다.
shuffle하는 과정은 train 데이터에서만 진행하였는데, 이 과정을 넣게 되면 성능 향상에 도움이 된다고 합니다.
그 이후 __getitem__이라는 keras의 메서드를 통해 이미지를 나타내게 되며, 나타나는 이미지는 train 데이터가 shuffle되었기 때문에 실행할 때마다 다른 이미지가 나오게 됩니다.
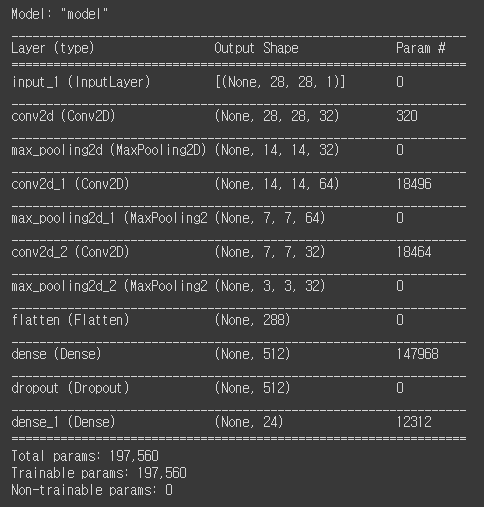
hidden layer의 깊이가 굉장히 깊습니다. Convolution 2D 값을 넣어 CNN을 구성한 후, MaxPooling하여 차원을 줄여갑니다. 이 과정을 필터의 개수만을 변경해주어 반복해주고, Flatten()을 통해 1차원으로 변경해주어 Dense Layer와 맞춰줍니다.
그 후 overfitting을 피하기 위해 30%의 노드를 랜덤으로 dropout시킵니다. 다중 회귀이기에 activation function은 softmax, loss function은 categorical_crossentropy를 사용하고 정확도를 출력하는 모델을 만듭니다.
출력 결과를 보면, total parameter의 개수가 deep nuural networks보다 훨씬 줄어든 것을 알 수 있습니다. 그러나 Dense Layer에서 parameter가 많은 부분을 차지하는 것을 알 수 있는데, Dense Layer를 줄일 수록 parameter를 줄일 수 있을 것 같습니다.
- 학습시키기
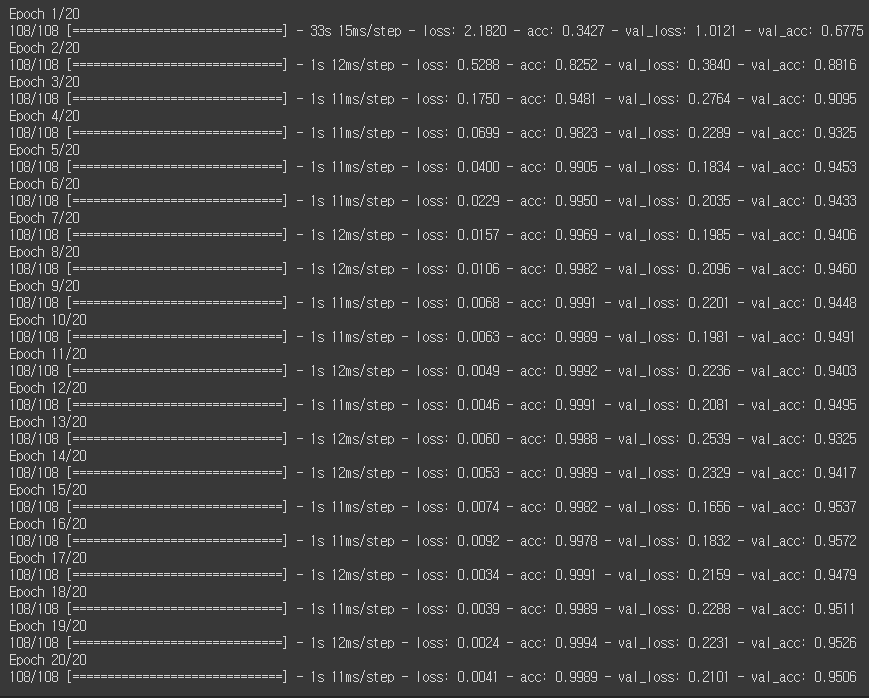
history = model.fit(
train_datagen,
validation_data=test_datagen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
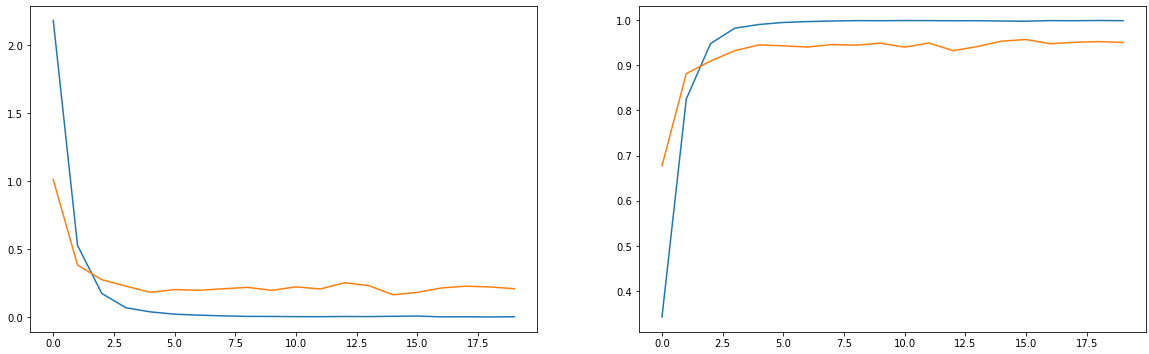
val_acc가 95%에 육박하는 것을 볼 수 있고, 이는 MLP에 비해 더 높은 성능을 보이게 됩니다.